Fastbook Chapter 1 Introduction
Fastbook Chapter 1 Book Notes
- Your Deep Learning Journey
- Neural Networks: A Brief History
- Who We Are
- How to learn DL
- The Software Stack: Pytorch, fastai, Jupyter
- First Model
- What is Machine Learning (ML)
- What is a Neural Network (NN)?
- Deep Learning Jargon
- Limitations inherent in ML
- How the Image Recognizer works
- What our Image Recognizer Learned
- Extending Image Recognizers to handle Non-Image Tasks
- More Jargon
- Other applications of DL
- Validation Sets and Test Sets
These are my notes from my reading of the fastai book by Jeremy Howard and Sylvain Gugger

Your Deep Learning Journey
Deep Learning is for Everyone
-
Deep Learning (DL) is a powerful tool that uses data to build powerful applications that would otherwise have been impossible to build using normal programming techniques.
- Can be applied across many disciplines
- Domain experts can find new applications for it
- Need more people with different backgrounds to get involved and start using it
- fast.ai was founded to spread DL into the hands of as many people as possible
-
Accessibility: DL is a technology that is accessible to normal folks. You don’t need:
- lots of math
- lots of data
- lots of expensive computers

-
Prerequisites: high school math, some coding experience required preferably Python
- but Python is easy to learn, lots of free online courses teach it.
-
Why learn DL? - Areas/Fields/Disciplines where DL is now best in the world:
- Natural Language Processing (NLP)
- Computer Vision (CV)
- Medicine
- Biology
- Image Generation
- Recommendation Systems
- Playing Games
- Robotics
- Others

Neural Networks: A Brief History
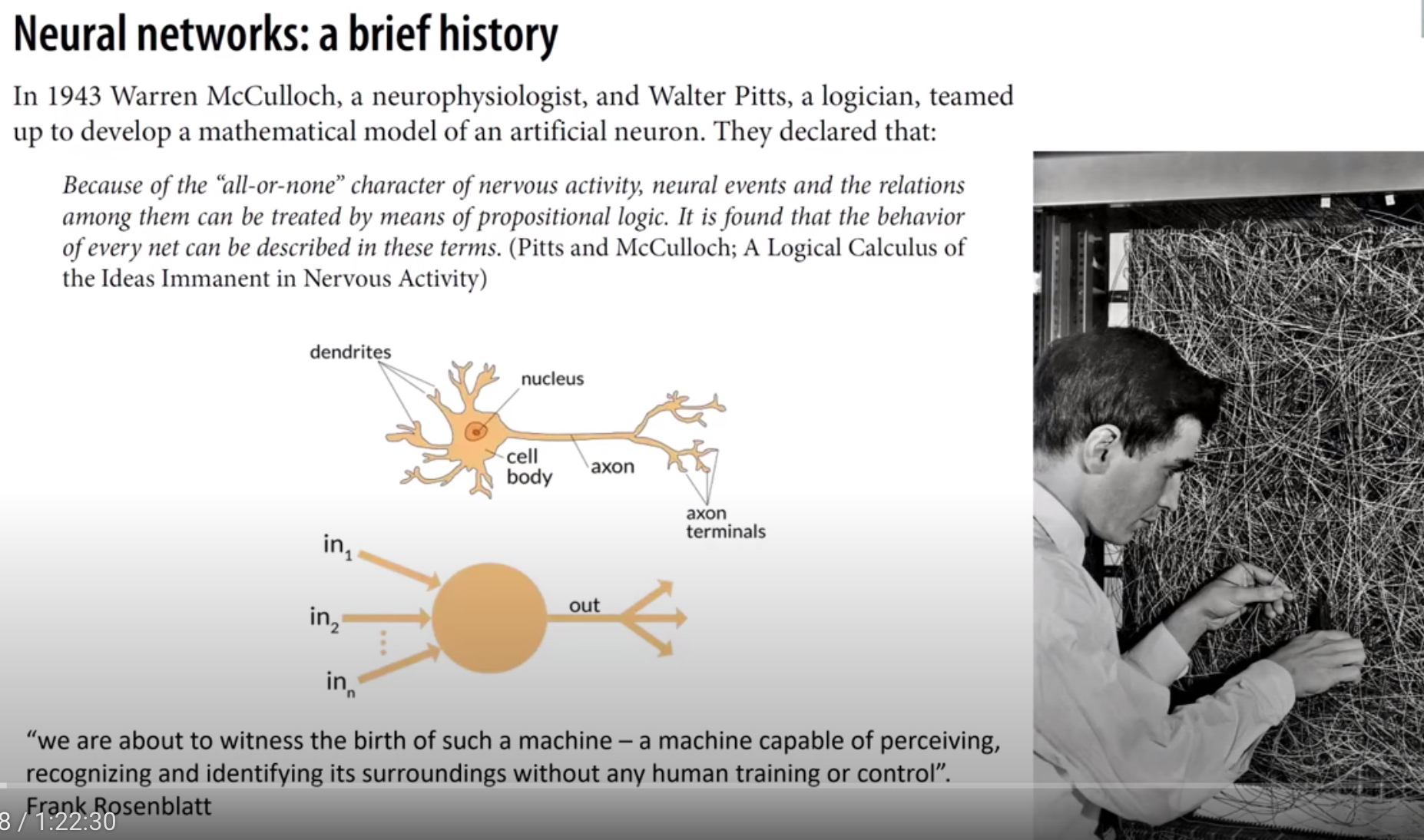
-
Warren McCulloch and Walter Pitts, 1943 - developed mathematical model of artificial neuron
-
Frank Rosenblatt, gave the artificial neural network (NN) the ability to learn, and built the Mark 1 Perceptron, a machine capable of recognizing simple shapes
-
Marvin Minsky & Seymour Papert wrote Perceptrons (book)
- asserted that NNs are limited
- 1 layer NNs can’t even compute XOR
- but also asserted 2 layers can compute more complex functions
- this was kind of disregarded, instead people focused only on the 1st assertion
- as a result, research on NNs was almost non-existent in the next 2 decades
- led to first AI winter
- asserted that NNs are limited
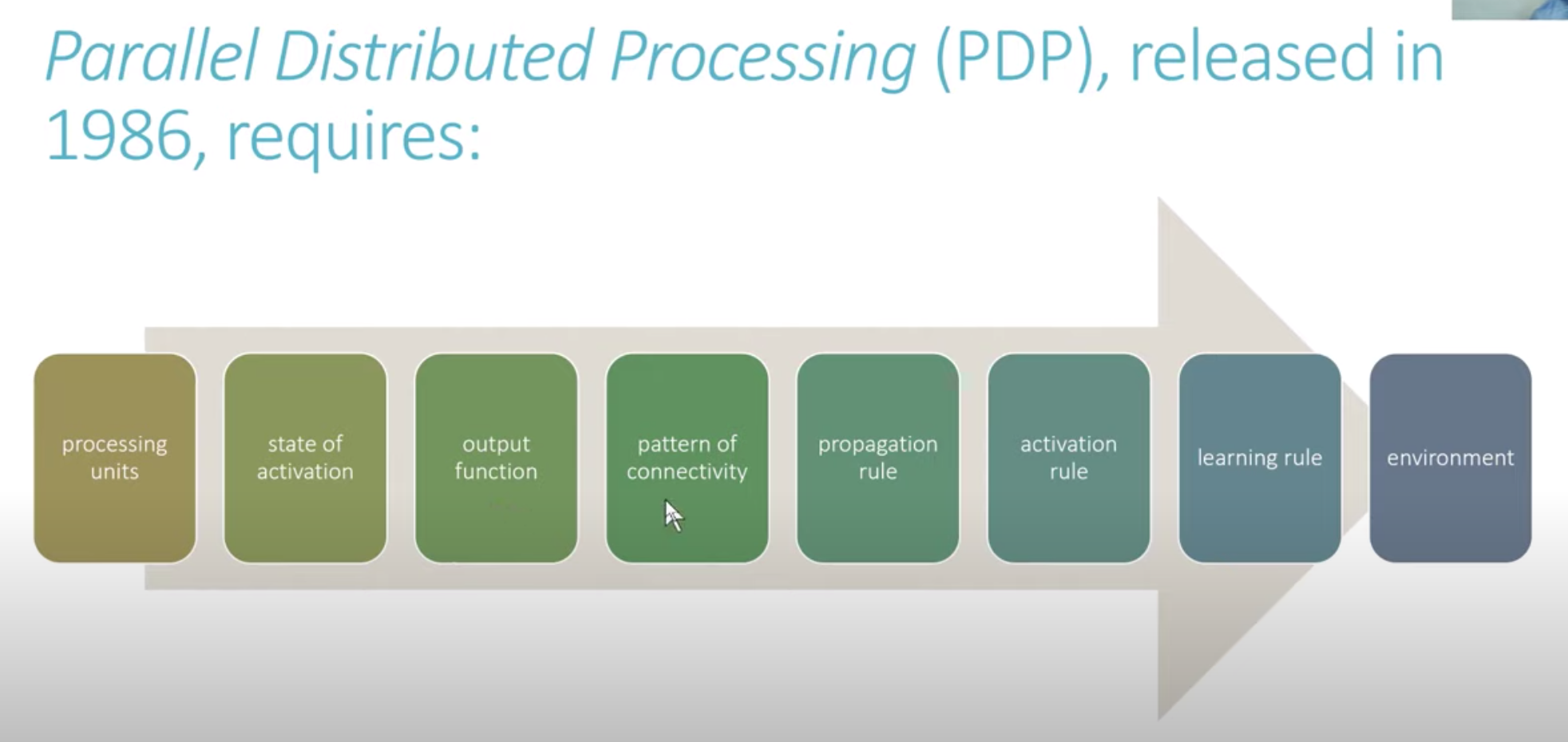
- In 1986, MIT published the 2 volume book Parallel Distributed Processing (PDP), where it asserts that a NN-based system requires:
- processing units
- activation state
- output function
- pattern of connectivity
- propagation rule
- activation rule
- learning rule
- environment
-
80’s and 90s - 2 layer NN began to widely used for real practical projects. but were too big or to slow
-
90s researchers showed that more layers needed to get practical good performance.
-
last decade - increases in data availability, improvements in hardware, algorithmic tweaks made deep neural networks practical and powerful.
Who We Are
- Jeremy, Sylvain, Rachel



How to learn DL
- Based on work by David Perkins, “Making Learning Whole”
- learn the whole game
- learn through examples
- simplify as much as possible
- remove barriers

- Code and try to solve problems - theory can come later.
- Much of deep learning is still artisanal and can only be learned by actual experience in building models and datasets.
- Tenacity is key - getting stuck is normal. rewind and read slowly if stuck, experiment and google.
- Apply to personal projects so you can sustain interest
Projects and Mindset
-
Get good test cases and projects
- focus on hobbies and passion
- try something not to ambitious at first, so that you don’t get stuck.
- set 4 or 5 little projects instead of 1 grand project.
- once you’ve done some little projects, go for bigger project you can show off.
- Character traits for success: playfulness and curiosity.
The Software Stack: Pytorch, fastai, Jupyter

- Jupyter notebook - provides the experimentation and documentation environment
First Model
- Setup your GPU DL Server
- use Cloud (e.g. Colab or Paperspace)
- Run your first notebook
- Course notebooks site
- Book site and book notebooks
- setup account (gmail for colab, email for paperspace)
- for paperspace - see paperspace setup
- for colab - see colab setup
- load notebooks
- for colab
- modify notebook for colab environment - see forum post
- setup google drive to clone course notebooks
- for colab
- view app_jupyter.ipynb
- run first notebook: Cats and Dogs Image Classifier
- duplicate and save notebook
- get dataset, create dataloader, create learner, train model
- do inference on model
- build image uploader and run inference on uploader using trained model: is this a cat?

What is Machine Learning (ML)
Deep learning is a modern area in the general discipline of ML
-
Normal Programs - make computer do a task by giving it detailed instructions
- inputs → program → outputs

- ML is an ALTERNATIVE way to get computers to do a task by giving it examples
- Arthur Samuels formulation (IBM, 1949) - 1962 essay - AI: A frontier of automation:
-
weights are assigned
- weights are variables - given a particular choice of values
- inputs are values processed to produce results,
- weights are other values that define how the program will operate.
- every weight assignment results in some level of performance
- automated means of measuring performance
- mechanism for improving performance by weight assignments
-
weights are assigned
-
Training Models
- inputs + weights → model → outputs + labels → performance → (update) → weights
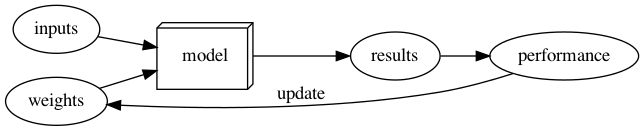
- using modern terms
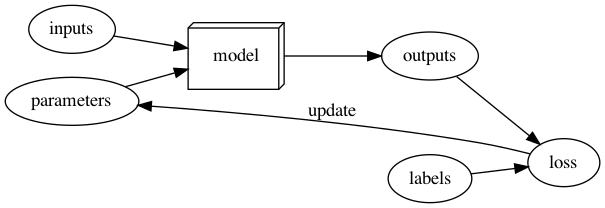
- Cat Dog Image Recognition Example
- inputs -> images of cats and dogs
- parameters -> “weights”
- outputs -> predict whether its a cat or dog
- label -> actual value whether image is a cat or dog
- loss - if output matches label -> loss is low, if output does not match label -> loss is high
- after measuring loss, update the parameters using SGD
- Inference (after training)
- inputs + weights (now part of model) → outputs

What is a Neural Network (NN)?
- A function that can compute any set of outputs given a set of inputs
- Universal Approximation Theorem - shows that neural networks can solve any problem to any level of accuracy.
- To find a way to update the “weights” of a NN in order to improve its performance, we use Stochastic Gradient Descent (SGD)
Deep Learning Jargon
- Architecture - functional form of the model
- Parameters - “weights” that form the model
- Predictions are calculated from the independent variables, which is the input data not including the labels
- Outputs of the model given its inputs (which are the independent variables) are called predictions *and are also considered the *dependent variables
- The measure of performance is called the loss
- Loss is dependent on the predictions plus the correct labels aka targets or dependent variables
- inputs + parameters → model architecture → predictions (outputs) + labels → loss → (update) parameters
Limitations inherent in ML
- A model cannot be created without data
- A model can only learn to operate on patterns seen in the input data used to train it
- The learning approach creates predictions not recommended actions
- It is not enough to have examples of input data, we also need the labels for the input data
- Need to think about how ML is applied since its predictions are sometimes used for recommendation systems that can predict what a user is most likely to do.
- Also need to think about the environment where ML is applied and how it interacts with the environment it is getting its data from.
- example : recommender systems creating feedback loops
- predictive policing model - amplifies existing racial bias in policing by predicting more crime in areas where POC are dominant and recommends more policing in those areas, leading to more arrests — arrests proxy for crime, so data (and models based on the data) will lead to a positive feedback loop.
- youtube videos recommending more extremist views to increase engagement — since videos with extremist views tend to be more engaging, system recommends those videos, leading viewers to espouse more extremist views and encouraging them to engage more with those types of extremist videos.
- example : recommender systems creating feedback loops
How the Image Recognizer works
Model Training Code sample
from fastai2.vision.all import *
path = untar_data(URLs.PETS)
def is_cat(item): return item.name[0].isupper()
dls = ImageDataLoaders.from_name_func(path, get_image_files(path),
label_func=is_cat,item_tfms=Resize(224),valid_pct=0.2,
seed=42)
learn = cnn_learner(dls,resnet34, metrics=error_rate)
learn.fine_tune(1)
-
from fastai2.vision.all import * :import fastai library - fastai2.vision.all package contains all the needed functions -
path = untar_data(URLs.PETS):download data from a URL -
def is_cat(item)...:define function to determine label based on filename- for the PETS dataset, if the name of the file is capitalized, its a cat, otherwise its a dog
- the type of the output or label determines the type of ML problem:
- regression - when output is continuous value
- classification - when output is a discrete set of values
-
dls = ImageDataLoaders.from_name_func...:defines how to load data that will be fed to the model using a dataloader object- what type of data is input (Image)
- what output is expected (
label_func=is_catto determine target label) - what transforms need to be applied to input data.
- item transforms - applied to each item (
Resize(224))- 224 is standard for historical reasons (pretrained model used 224x224 as image size)
- can increase size for better detail and possibly better results, but more resource intensive, reducing size reduces detail, but can run much faster with less memory
- batch transforms - applied to a batch of items (typically on GPU so its fast)
- item transforms - applied to each item (
- split validation from training sets - by default 20% of input is randomly selected as validation with a set
seed=42(to fix the splitting)-
why split into training and validation sets?
- NNs can “memorize” the training data, which will make model predict well with data used in training, but will not generalize to other data not used in training.
- By setting aside data in a validation set, this data in the validation set is not used in training, but is used to monitor overfitting.
-
Overfitting occurs when NN is optimizing on training data but performance on validation set is worsening.
- Overfitting is one of the most important and challenging issue in ML
-
why split into training and validation sets?
-
learn = cnn_learner(...:create cnn learner with architecture and metrics using dataloader- set validation metrics to show model performance and monitor overfitting
- Metrics is different from loss - metrics measure quality of model predictions, loss is used for tracking how the performance changes as model parameters are changed (used in training)
- set validation metrics to show model performance and monitor overfitting
- set the architecture - in our case
resnet34- different architectures available
- example resnet34 comes with 34 layers, resnet50 with 50, resnet152 with 152 layers, etc
- visualize the NN as consisting of layered cake - with the inputs (images) entering from the bottom and the predictions coming out from the top (aka the head)…
- NN with 50 and 152 layers are bigger than one with 34 layers, resnet18 is the smallest in the resnet family.
- smaller NNs are faster to train, larger NNs are more powerful in capturing nuances (in general)
- to find the ideal size, you have to experiment - but resnet34 is usually a good compromise and default
- there are also other families and variations within familities of architectures
- example resnet34 comes with 34 layers, resnet50 with 50, resnet152 with 152 layers, etc
- different architectures available
-
pretrained flag - default to true - use pretrained weights - where a model trained in a different related task is reused for another task, reducing the amount of training time and data needed to achieve good performance.
- pretrained will remove the last (topmost) layer and replace with 1 or more randomised layers specific for your task.
- using a pretrained model is the most important method to allow us to train accurate models, more quickly with less data and less time and money.
-
Transfer learning - using a pretrained model for a task different from what it was trained for.
- Most important technique to reduce resources (data, compute, time) needed to train models to acceptable or even state of the art (SOTA) performance
-
learn.fine_tune(1):fit (i.e. train) the model to your task.- 1 is the number of epochs - the number of times your model looks at each sample of input data.
- there is also a
fitmethod that does fit the model, butfine_tunedoes additional “tricks” to adapt a pretrained model for a new dataset, a process known as fine tuning.- fine tune - 1. use one epoch (aka freeze_epochs parameter defaulted to 1) - to train just the head, with the rest of the model frozen
- unfreeze the lower layers, and train using the discriminative learning rates, where the lower layers (which need less adjustments since it has already been pretrained) are trained with lower learning rate, the head (which starts with random values) is trained with higher rates
- the learning rate is a “hyperparameter” - a knob that is used to tweak the training of the model in order to make the model achieve a better level of performance faster.
What our Image Recognizer Learned
- the model might be performing well, but its still a “black box” as to what its really doing (this is a known problem in ML).
- there are techniques to inspect DL models and get insights, but it can be challenging to understand, especially when they encounter data that is very different from the one used in training the model.
- Zeiler and Fergus, 2013 - Visualizing and Understanding CNNs - visualization of NN weights learned in each layer.
- lower layers - simple shapes
- higher layers - more complex shapes combined from lower layers


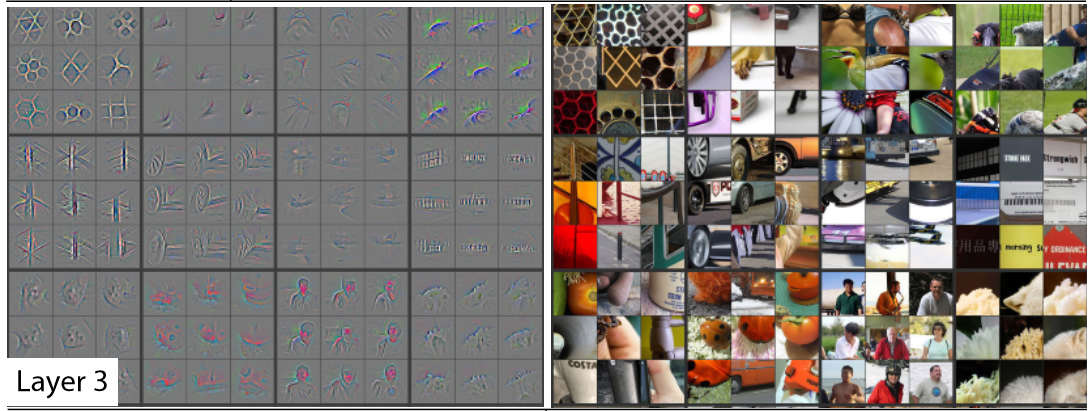

The model (Alexnet) studied had only 5 layers so deeper networks even can recognize even more complex features. The upper layers (ie. the head) are specialized for the task specific to your model (distinguishing cats from dogs) and so require higher learning rates compared to lower layers which share more or less the same features as the pretrained model.
Extending Image Recognizers to handle Non-Image Tasks
One way to extend image recognizers is by converting data into images which can then reuse pretrained image models.
Examples
- Sound - converted to spectograms - see this article using fastai for audio classification

- Mouse movements - Splunk converted recorded mouse movements into images which were then used to train a bot detector - see this article
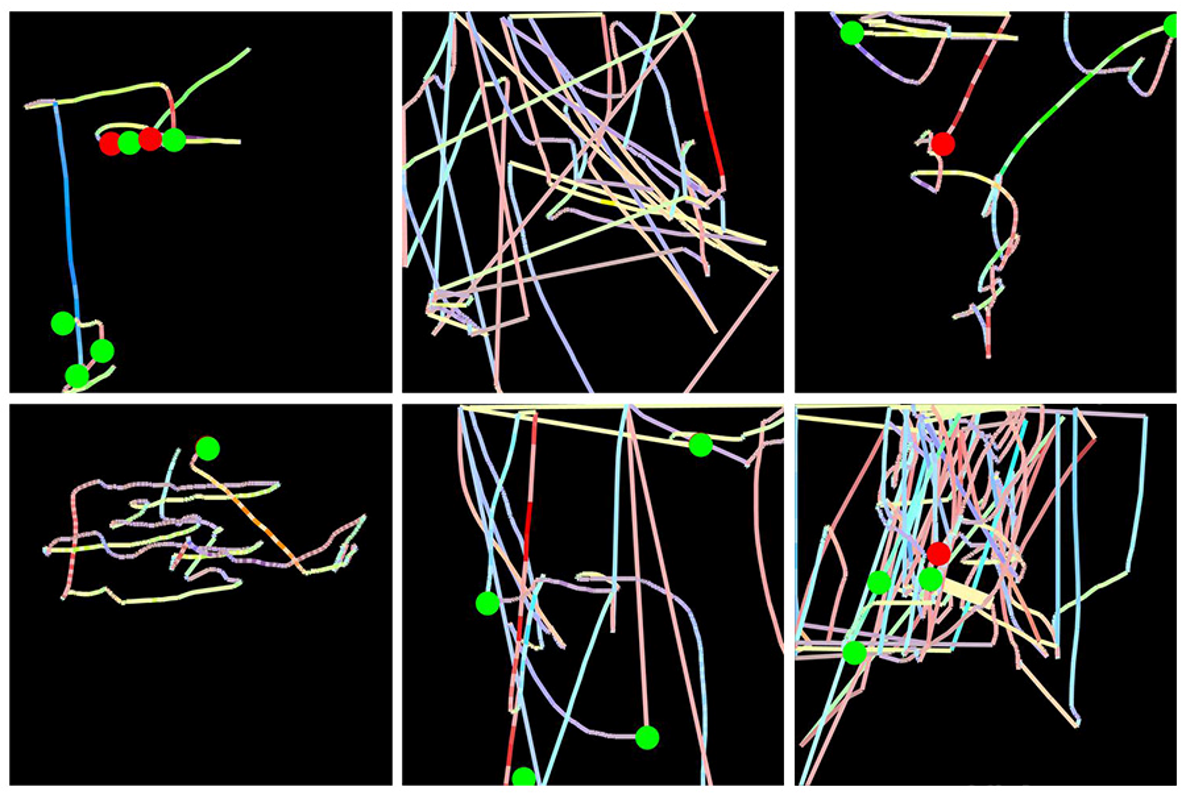
General tip: if your data can be converted to image data and the images can be classified by humans looking at the images, chances are image recognizers using transfer learning can be trained to classify them as well.
More Jargon
- Label
- Architecture
- Model
- Parameters
- Fit
- Train
- Pretrained Model
- Fine tuning
- Epoch
- Loss
- Metric
- Generalization
- Overfitting
- Training Set
- Validation Sets
- Convolutional NNs
Other applications of DL
-
Image Segmentation - label each pixel with object it belongs to
- CamVid example using subset of data from the paper Semantic Object Classes in Video: A High-Definition Ground Truth Database

-
Sentiment Classification (Natural Language Processing or NLP) - tells you if movie review is positive or negative
- Movie Review Sentiment Classification using IMDB data from the paper Learning Word Vectors for Sentiment Analysis
-
Tabular Data - predicts income based on multiple factors such as age, educational attainment etc.
- Income prediction using Adult dataset
-
Recommendation Systems
- Movie Recommendation using movie lens dataset
Validation Sets and Test Sets
- train set - data seen by model during training
- validation set - used for evaluating model - test model to generalize and tweak it appropriately (hyper parameter tuning)
- test set - data reserved for predicting performance in the real world (after tweaking)
- TIP for creating validation and test sets - simulate data that will be encountered in production - random subsets may not always be best way to select validation - e.g. time series data - should use continuous data in the future w.r.t. to data used or images not in training data (assuming they occur multiple times)