Fastbook Chapter 2 Production
Fastbook Chapter 2 Book Notes
- From Model to Production
These are my notes from my reading of the fastai book by Jeremy Howard and Sylvain Gugger
From Model to Production
-
Chapter Objective: Learn the end-to-end process of building DL application
- collect data
- build model
- deploy app
The Practice of Deep Learning
- DL can solve a lot of challenging problems that were previously hard to solve.
- As a DL beginner - find sweet spot of problems
- similar to example problems
- get extremely useful results
- but DL is not magic!
- same lines of code wont work for all problems
- As a DL beginner - find sweet spot of problems
- To learn DL quickly
- find sweet spot of challenging problems
- quick to get extremely useful results
- but difficult enough to always learn something new
- find sweet spot of challenging problems
- Understanding capabilities and constraints of DL
- underestimating constraints and overestimating capabilities of DL
- can lead to poor results, consequently frustration
- overestimating constraints and underestimating capabilities
- can lead to reticence in applying DL, even when it can be reachable
-
Summary:
- underestimating capabilities can lead to reticence in applying DL
- underestimating constraints can lead to failure to consider and react to issues arising from using DL
- best to keep an open mind
- DL might solve part of your problem with less data or complexity
- Design a process to find specific capabilities and constraints related to your particular area
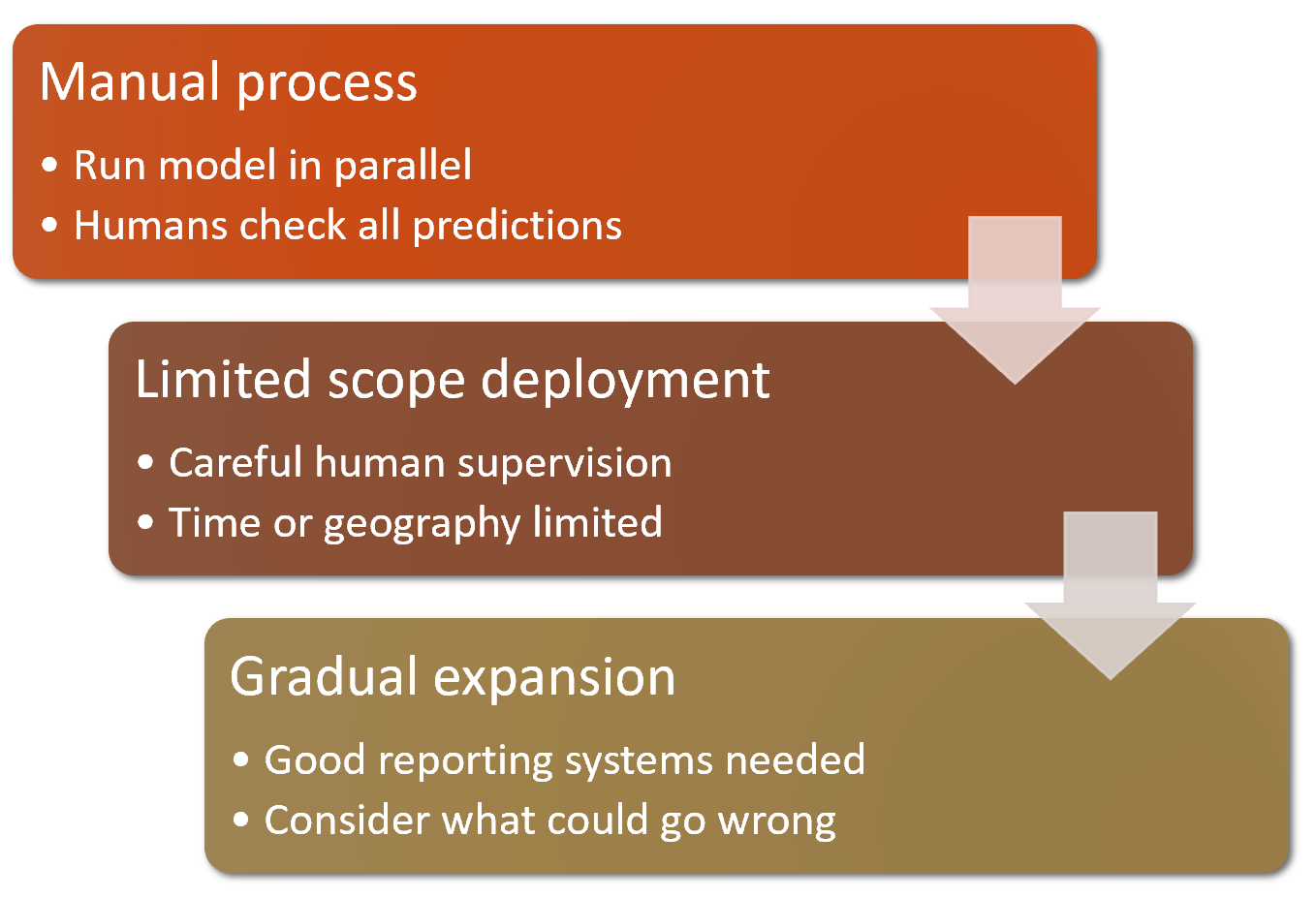
- No risky bets - gradually roll out models so they don’t create significant risks
- backtest prior to production
- underestimating constraints and overestimating capabilities of DL
Starting your project
- Ensure that you have a project to work on
- only by working through projects will gain experience building and using models
- Considerations in looking for your project
- most important consideration: data availability
- get started quickly
- iterate quickly - goal is not to start with “perfect” dataset, but start and iterate quickly
- iterate end-to-end
- dont spend too much time polishing each step
- complete every step in reasonable time
- do it all the way to the end and then come back to iterate again and again
- evaluate process to find areas to focus on that make the biggest gains in end result
- work through the book
- complete lots of small experiments
- by running and adjusting the provided notebooks
- at the same time, gradually develop your own projects
- get experience with all tools and techniques discussed in the book
- learn by practicing and failing
- DL is still artisanal practice
- nothing beats applied practical experience in training models
- backed by theoretical understanding of DL principles
- show effective results
- nothing beats a working prototype
- get organization buy-in for DL projects
- Easiest to get started on projects
- where data is already available (e.g. public datasets)
- related to something you are already doing (where you already have access to data)
- be creative if data is not available
- find related data in a similar domain or tackling a slightly different problem
- working on related domain will still help you identify shortcuts or workarounds
- When starting DL, Not a good idea to branch out to different areas
- esp. areas where DL has not been applied before
- if you have problem - you wont know whether
- you simply made a mistake or
- DL is not a good fit for the application
- hard to look for help
- Start with a problem that someone else had good results
- similar to what you are trying to achieve
- or you can convert data to some similar format
- look at areas where DL has been successful
- complete lots of small experiments
The State of Deep Learning
- Consider whether DL is a good fit to your application by looking where DL capabilities are mature.
- but DL is evolving quickly, so previous historical constraints may have been overcome by latest research
Computer Vision
- Areas where DL is mature:
- object recognition - what items are in an image (e.g. everyday objects, faces, medical images - xrays, MRI, - cancerous lesions, etc)
- object detection - where the objects are in an image
- variant: segmentation - what object each pixel belongs to
- DL image recognition may not be good
- recognizing images that are significantly different from ones used in training
- eg. if no black/white images in training data, model might not be good when used on b/w images.
- also not good for hand-drawn images if they are not part of training data.
- no general way to check for missing types of images in training data
- but there are ways to check if unexpected image types are encountered in production
- AKA checking for out-of-domain data
- but there are ways to check if unexpected image types are encountered in production
- Labeling image data can be slow and expensive
- currently requires manual effort
- lot of effort to make this better
- tools to make labelling faster and easier
- require handcrafted labels to train accurate object detection models
- one useful technique: data augmentation
- synthetically generate variations of input data to improve capability of model
- one useful technique: data augmentation
- Another possibility is to convert your data (which may not appear to be a computer vision problem) into images
- images may then be amenable to computer vision algorithms for detection
- example: convert audio to images of acoustic waveforms and use object detection to solve audio detection problem
- recognizing images that are significantly different from ones used in training
Text (NLP)
- DL in NLP is good at:
- classifying short/long docs on
- spam/not spam,
- sentiment (positive/negative review)
- author, source website, etc.
- generating context-appropriate text
- but currently not good at generating correct responses
- can be dangerous, as text can be used for mass disinformation
- Other NLP applications
- translate one language to another
- summarize long documents
- find mentions of a concept
- but translations and summaries can contain incorrect information
- actual usage: google translate and other online translation services - use DL
- classifying short/long docs on
Combining Text and Images
- Combine text and images into single model
- example DL app: generate captions for images
- but no guarantee for accuracy
- need to have human oversight due to possible errors
- can be more productive/accurate than manual process with humans alone
- example DL app: generate captions for images
Tabular Data
- Analyzing time-series and tabular data, DL has made great strides
- DL is generally used as part of ensemble of multiple types of models
- DL is not a great improvement over RF (random forest) or GBM (gradient boosting methods)
- but can handle columns with greater cardinality or columns with text (by using NLP)
- Downside: DL takes longer to train than RF or GBM
Recommendation Systems
- very similar to tabular data, except they usually have a high-cardinality categorical variables represent users and products (or something similar - eg. movie review)
- represents data as a sparse matrix (customers as rows and products as rows) representing purchases by a customer of a product
- Apply collaborative filtering to fill in the matrix - this is used to make recommendations
- Can combine other types of data -eg images, text, additional metadata such as customer information, previous transactions etc.
- Can only predict, but not recommend - need to analyze how to turn predictions into recommendations
Other Data Types
Other data types also exist
- Protein chains and genome sequences - can use NLP techniques
- Audio recordings - convert to image as spectograms - can use CV techniques
The Drivetrain Approach
- Ensuring effective application of DL
- DL can create accurate models but not useful
- DL can also create inaccurate models that are useful
- need to consider how your work will be used
- Drivetrain Approach - created by Jeremy, Margit Zwemer and Mike Loukides
- discussed in book Designing Great Data Products
- basic idea:
- start considering objective
- think about actions to take to meet objective
- what data you have or can get to help decide on the action
- build a model that can be used to determine best actions to get best results for your objective
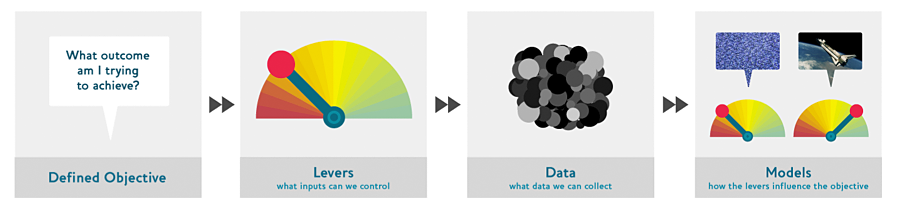
- Models are usually part of solution, they become part of the plumbing
- Use data to produce actionable outcomes
- Example: Google Search
- define clear objective: what is user main objective in search? - find most relevant search result
- consider levers for this objective: ranking of search results
- consider data needed to produce ranking: implicit info based on links between pages provides rich data to determine which page is most relevant
- after the first 3 steps, and determining what data is available and what data is needed, then build model to meet objective
- Example: Recommendation Systems
- objective: drive additional sales by recommending items which customers would never have purchased without the recommendation
- lever: ranking of the recommendation
- data needed: new data to generate recommendations to trigger new sales
- require randomized experiments to collect data about wide range of recommendations for a wide range of customers (required to have info usable to optimize recommendations to increase sales)
- build two models - purchase probabilities conditional on seeing or not seeing the recommendation
- the difference between the two models is a utility function for a given recommendation
- low if algo recommends a familiar book already rejected by the customer
- low if algo recommends a book they would buy even without the recommendation
- high if algo recommends a book they would not have bought without the recommendation
- the difference between the two models is a utility function for a given recommendation
- in practice, implementation of model requires more than just training the model.
- also need to run experiments to collect more data
- also need to consider how to incorporate models into the overall system
Gathering Data
- How to find data for your project
- For some projects, data needed might be online
- Bear detector project
- first project to build end-to-end model to app
- distinguish between black, grizzly and teddy bear images
- internet database of bear images is available
- need to find and download bear images
- Current Example: Bing Search Images
- Signup at Microsoft - comes with Bing Image Search
- see course notebook
- see book chapter
- API Key Page - after login - get API key here
- key = ‘xxx’
- search and get image urls
results = search_images_bing(key, ‘grizzly bear’) ims = results.attrgot(‘content_url’) len(ims) dest = ‘images/grizzly.jpg’ download_url(ims[0],dest) im = Image.open(dest) im.to_thumb(128,128)

- use
download_imagesto download grizzly bears, black bears and teddy bears - download images to a different subfolder for each type
- use
get_image_filesto retrieve all images under common bears folder - use
verify_imagesto get corrupted images andPath.unlinkto delete them
Sidebar: Getting Help from Jupyter
- use
??<method_name>to show source - use
?<method_name>to show doc - use
<Tab>to get autocompletion - inside parenthesis, use
<Shift-Tab>to get function signature and short doc,-
<Shift-Tab>twice to show more doc -
<Shift-Tab>thrice to open a full window
-
-
doc(<func_name>)will open a window and links to source on Github plus full doc -
%debug- open Python debugger which will let you inspect the contents of every variable
Bing Image Search Results
- Since models can only reflect data used to train them, and if the data used to train the models is *biased *then the model will also produce *biased results *
- example : Bing Image Search for healthy skin
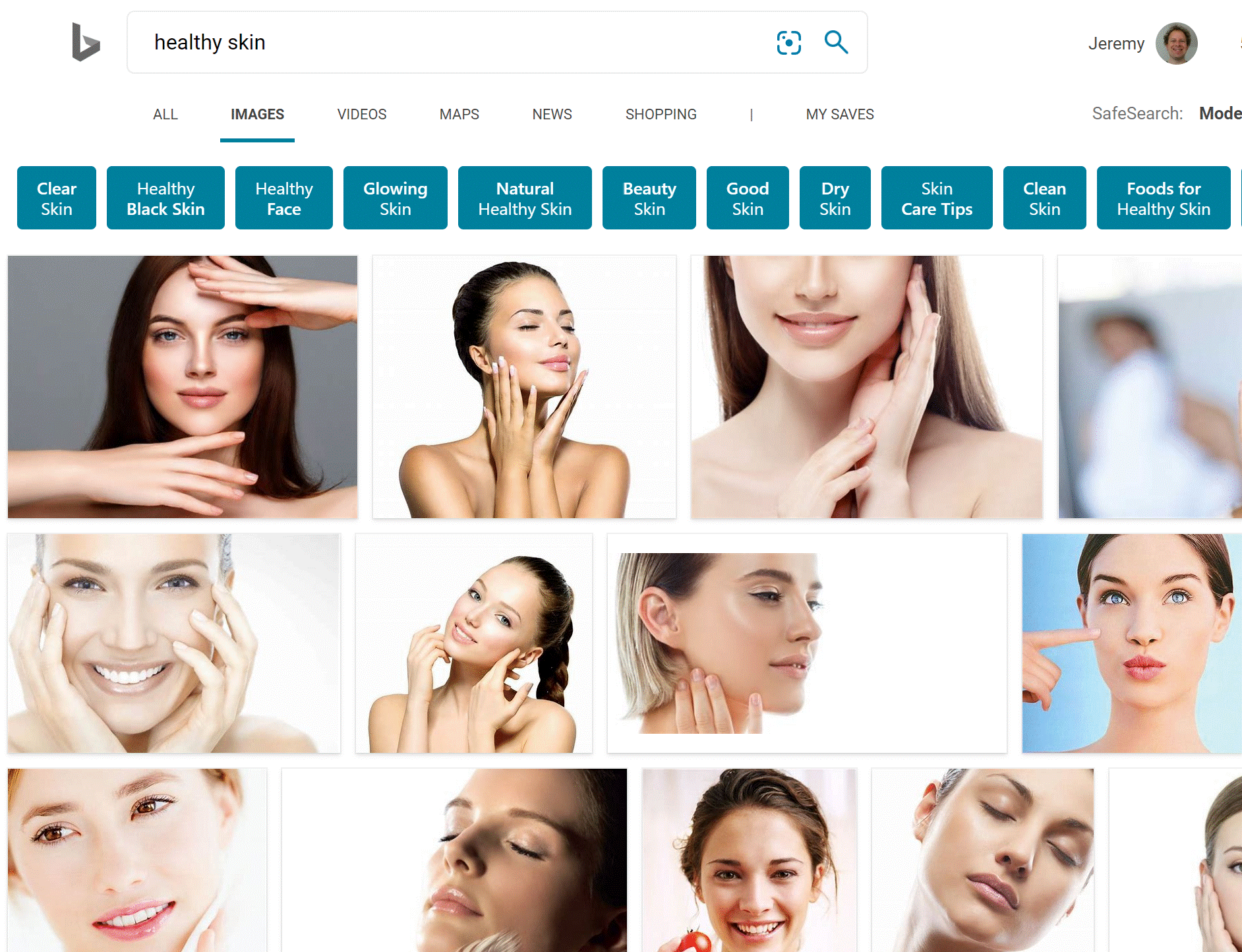
- Be careful about using images without inspecting them - even commercial search images can produce biased results.
- See “Actionable Auditing: Investigating the Impact of Publicly Naming Biased Performance Results of Commercial AI Products” for more examples
From Data to DataLoaders
Now that data has been captured and stored in segregated folders, we need a process to load the image data and feed them to model for training.
- The components responsible for loading the data are the DataLoaders
-
DataLoaders are composed of multiple *DataLoader **objects passed to it - normally the *train dataloader and the valid dataloader
class DataLoaders(GetAttr): def init(self, *loaders): self.loaders = loaders def getitem(self, i): return self.loaders[i] train,valid = add_props(lambda i,self: self[i])
- DataLoader specifications:
- What kinds of data we are working with (Image, Category)
- How to get a list of items
- How to label these items
- How to create the validation set
- DataLoaders have factory methods for the most common combinations of these components
- example:
ImageDataLoaders.from_name_func(
- example:
-
MORE FLEXIBLE ALTERNATIVE is the DataBlock API
bears = DataBlock( blocks=(ImageBlock, CategoryBlock), get_items=get_image_files, splitter=RandomSplitter(valid_pct=0.2, seed=42), get_y=parent_label, item_tfms=Resize(128))
-
blocks=(ImageBlock, CategoryBlock) -tuple to specify what types for dependent (category - type of bear) and independent(image) variables -
get_items=get_image_files- underlying items are file paths (to each image) -
splitter=RandomSplitter(...- randomly split 20 percent of data for validation and the rest for training, with a seed=42 so that the split is repeatable)
Data Augmentation
Training your Model to Clean your Data
Turning your Model into an Online Application
Using the Model for Inference
Creating a Notebook App from the Model
Turning Your Notebook into a Real App
Deploying your app
How to Avoid Disaster